TLDR A simple metrics-based ranking system is good enough to decide who gets how many resources.
Computational resources – CPU time, memory usage, network traffic etc – are limited. This may be more or less of a problem depending on project/company size and so on; if you’re working on a smaller product with limited traffic, it might not be meaningful at all.
Once past a certain threshold though, expenses with such resources become non-trivial and it begins to make sense to spend some time thinking about how to distribute them as efficiently as possible.
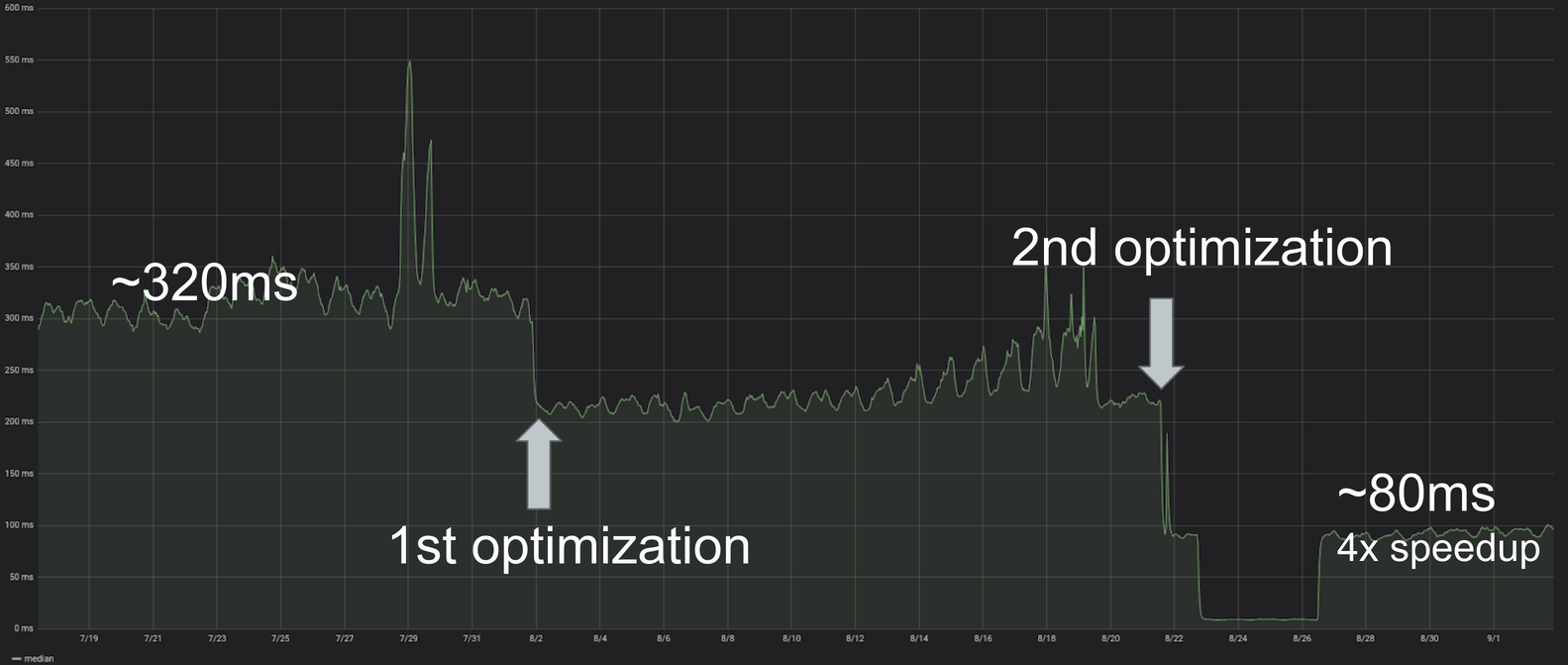
Here’s the problem that got me thinking about this: at work, we had a computational resource that needed to be consumed by a large fleet of workers (think several thousand concurrent), but each type of worker had different productivity, and that productivity changed over time. How can we decide who gets what?